AI and the Hype Cycle - Where are we?

Obviously, AI is all the rage lately, and I wanted to delve into it a little bit. Now, I have a bit of a unique perspective on it, as AI and Machine Learning (ML) were the main focus of my Masters work, and I've implemented many of the training and evaluation algorithms that are the core of what is used today.
One of the interesting things when it comes to AI is that many of the techniques and algorithms in the field have been around for 50 or more years, but are only now becoming available more generally. What changed? Two big things, specifically: (1) having the computing power available to compute in a timely manner, and (2) having data storage become so cheap and ubiquitous that there's plenty available for training.
Plus, AI is a fairly big bucket that covers several different approaches to Artificial Intelligence, including Machine Learning (ML), Large Language Models (LLMs), Natural Language Processing (NLP), Generative Pre-Trained Transformers (GPT) and many other techniques, each with it's own level of maturity. For example, I worked to implement both ML and NLP models during my graduate research in the early 2000s and both have standardized many of their approaches since, but LLMs and GPTs have really only emerged in the last decade.
Now, because of this, one could argue that we are at any number of spots on the curve, and we're honestly probably at a different point with each type. Let me break down where I think we are currently at with the "Big 4":
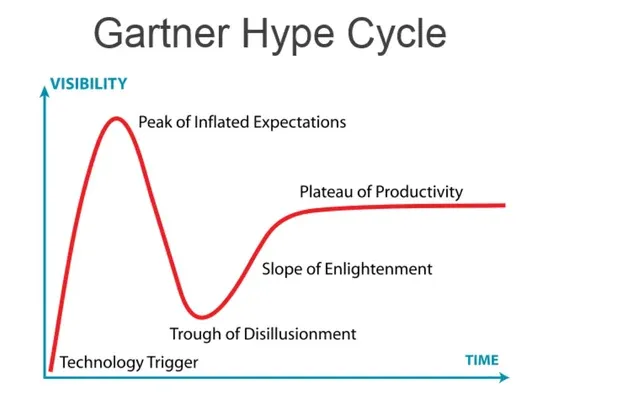
Machine Learning is probably the most mature technology among the bunch, and likely on the Plateau of Productivity, mostly because it is the most transparent of the bunch. Many recommendation and decision-making frameworks will leverage ML, like a streaming recommending what to watch next after finishing a series. However, these may also be combined with other factors to provide a recommendation, like pushing a recency bias or adjusting the recommendation based on how much was paid to acquire the media rights.
While Natural Language Processing may not get the hype of Large Language Models, they are currently very efficient and effective when applied to specific domains, such as such a scientific research discipline, or legal practice area. I'd put them on the Slope of Enlightenment, as there was definitely a dip in excitement when they didn't scale well to general-purpose inquiries, but they have proven to be a powerful and useful tool when used properly.
Ironically, even though GPTs depend on LLMs, I do believe we're at two different points with them.
GPTs are clearly on the downward slope from the Peak of Inflated Expectations to the Trough of Disillusionment with the two biggest problems being the "hallucinations" and implicit bias. While I've heard "hallucinations" being attributed to "learning" or even being pushed as a "good thing", they're clearly unintended outputs based on the models that have come together, akin to a student trying to sound smarter and using words they don't understand incorrectly. And since neural nets, the technology underlying LLMs and GPTs, are inherently black box approaches, they have to be retrained to eliminate those issues, which is an expensive and time-consuming action. So, when you see the release of a new model or version, that's what has been done. The software is virtually unchanged, but the retraining for the desired outputs has been completed.
Then there's the implicit bias, which are usually unintended outcomes based on the biased information being fed into the model for training. I'm sure most black Americans and women can provide numerous examples that they encounter daily, but even if you try to exclude race and gender explicitly, models could pick up on the biases through implicit means, such as names, location, and personal histories. If your goal is to be as neutral as possible, then these implicit biases need to be addressed in the training process. And since most businesses are approaching AI with the "do what we do now, but with AI" mentality, most of these implicit biases are not just being included, but oftentimes enhanced.
Lastly, LLMs are probably trailing GPTs on the curve, and closer to the Peak of Inflated Expectations for two reasons. First, LLMs are more general-purpose, being the training and neural net development that powers GPTs or can be tuned towards more specific mathematical and scientific research models. Second, while they often power GPTs they are less visible to many users, so when there are issues, they are less likely to receive blame, even if they may be the source.
All that said, it's an ever-changing time when it comes to AI, whether it's the big players releasing new models to try and please everyone, or the emerging AI company who is training a niche model for a specific industry or purpose, things are changing almost daily, and these takes are likely to change quite a bit over the next year or two.

Comments ()